Streams and React Server Components
January 13, 2024
Many developers have used streams when building technology, but how many have truly understood their intricacies and their connection to React Server Components? Personally, the concept never quite clicked for me. It wasn't until contributing to Waku and being curious about how RSCs stream html—requiring me to take them seriously. Waku is a minimal layer over React Server Components using Vite.
In this essay, I'm going to talk more about the concept, the abstraction the Streams API provides around the concept and how React Server Components leverage this API.
Concept
data that is created, processed, and consumed in an incremental fashion, without ever reading all of it into memory. whatwg
Well, streams are a way of handling data sequentially! for instance, instead of reading the whole file into the memory which can exhaust the resources, you'd handle the file chunk by chunk (by dividing it).
const response = await fetch(url);
for await (const chunk of response.body) {
// Do something with each small "chunk"
}
This saves memory, as you handle one chunk at a time instead of the whole file. Reading that file becomes almost instantaneous, as soon as your computer process the first chunk, it'd pass it to you without waiting for all the data to be processed.
A chunk is a single piece of data that is written to or read from a stream. It can be of any type; streams can even contain chunks of different types. whatwg
The web streams API, just provides a standard API for this concept, that not only handles files, but any form of data!
// All these methods embed the whole response in memory and return all of the results as opposed to response.body
response.blob()
response.text()
response.json()
RSC and Transfer-Encoding: chunked
While curious about how the React team streams the html, most Google articles referred to streaming videos with HLS (HTTP Live Streaming), which wasn't the desired information. It wasn't until I stumbled upon this mdn document.
This header means that the response I'm sending is divided into multiple chunks and we can add to those chunks in a non-blocking way after the initial response. The key is that React just returns a stream (ReadableStream for edge, and a pipe method for Nodejs Streams ) and would let the server handle the rest!
In Nodejs or Cloudflare workers, the Transfer-Encoding: chunked header is set for the response since the response body is a stream.
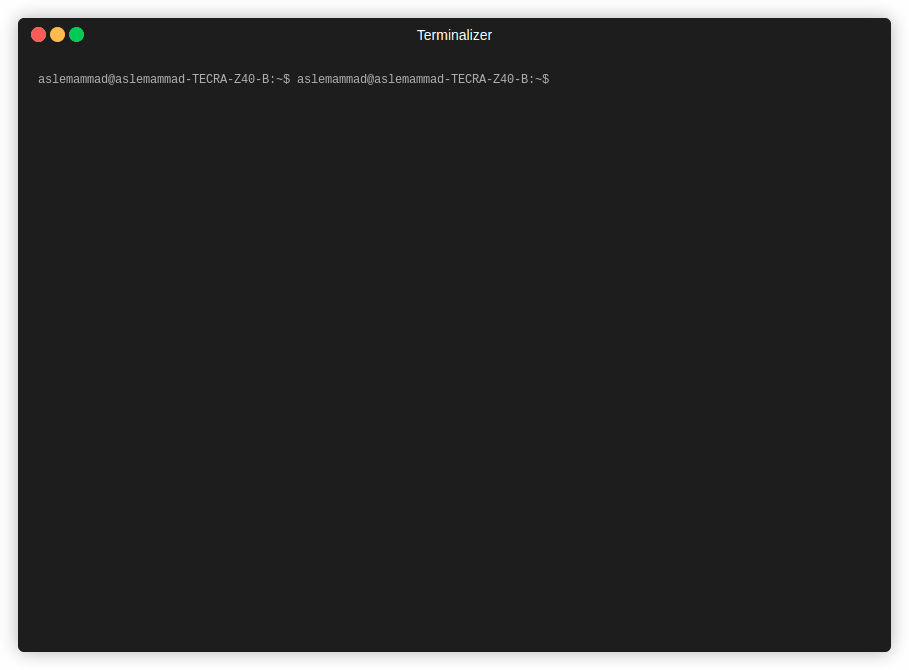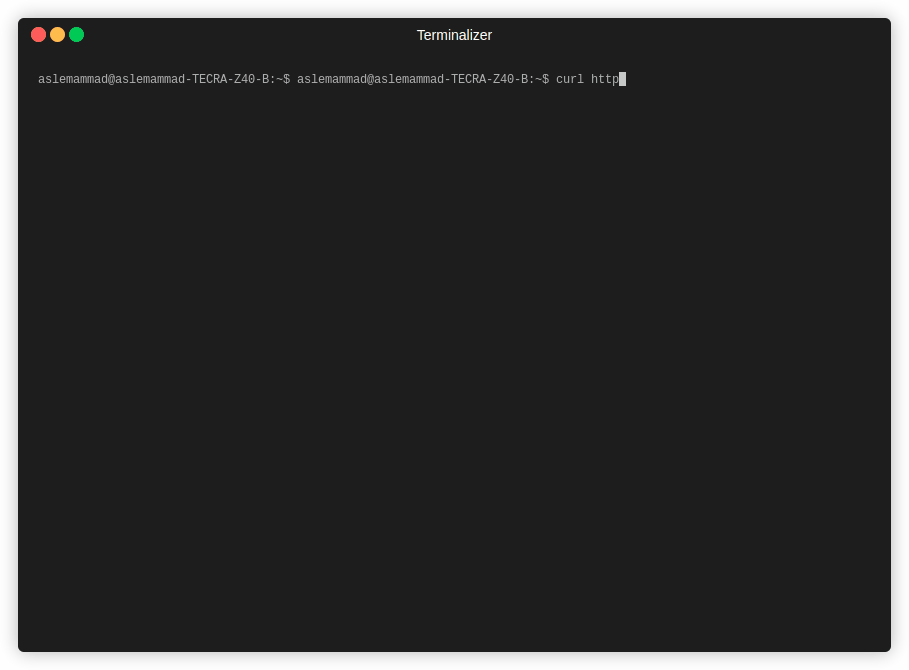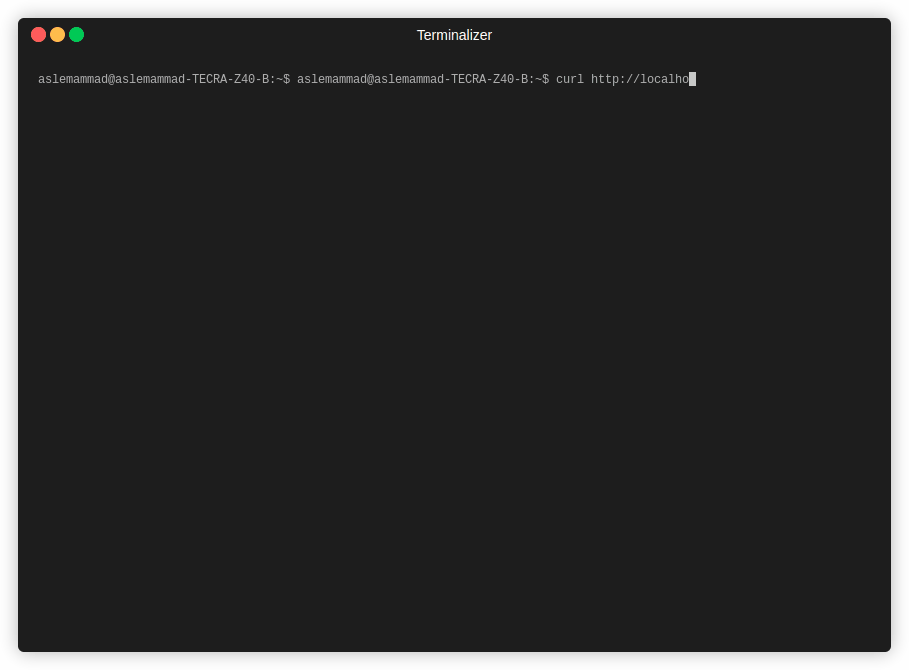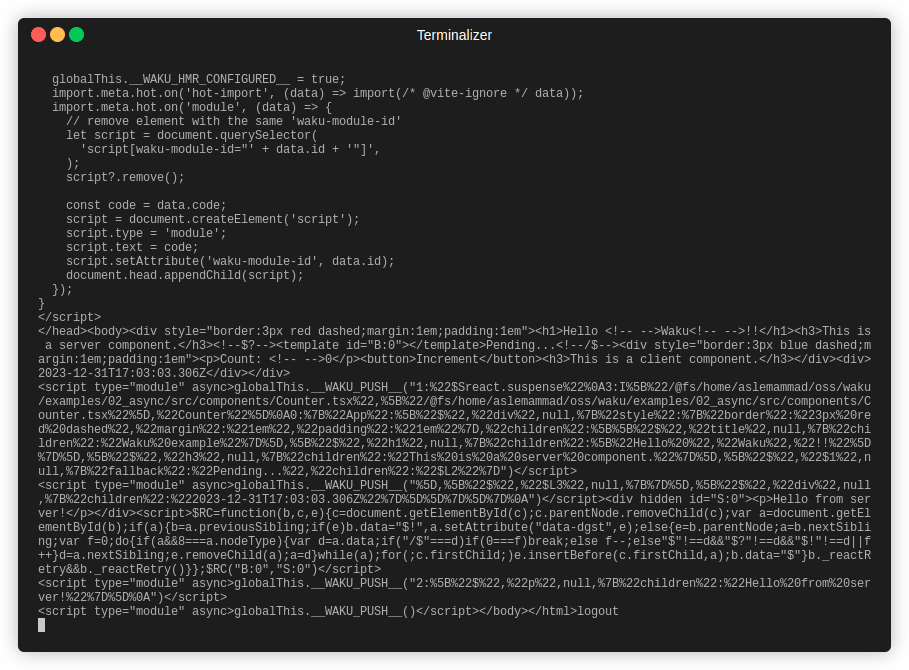
RSC streaming an html document using a ReadableStream in Waku.
ReadableStream
// Fetch the original image
fetch("./tortoise.png")
// Retrieve its body as ReadableStream
.then((response) => response.body)
// https://developer.mozilla.org/en-US/docs/Web/API/Streams_API/Using_readable_streams#consuming_a_fetch_as_a_stream
It's a stream that you're supposed to read from, simple as that, and you cannot write (enqueue) to it unless you are the one who's providing the stream itself which you'll have access to an object called the controller at that point!
// you might want to open the console and try running this code
let controller;
const readable = new ReadableStream({
start(c) {
controller = c
}
})
the start method runs when you instantiate the ReadableStream class and then you get the controller (ReadableStreamDefaultController).
controller.enqueue('chunk 1')
controller.enqueue('chunk 2')
controller.enqueue('chunk 3')
controller.close() // no more data
When receiving a ReadableStream from another source, like the fetch API, you won't have the ability to write data into it because you do not have access to the controller. Additionally, it makes sense, that you cannot modify a response coming from the server :)
Pull
Matteo highlighted the pull method as a better way to add data to readable streams, something I wasn't familiar with. The pull method is triggered when the consumer actively wants to receive data, unlike start, which activates when the readable stream is created.
In the earlier examples, data was added without considering if the consumer needed it. In such cases, the stream behaves like a push source. By using the pull method, we transform our stream into a pull source. This allows the stream to provide the necessary data only when needed. Here's an example.
Reader
For reading from a readable stream, we need a reader.
const reader = readable.getReader()
await reader.read()
// {done: false, value: 'chunk 1'}
await reader.read()
// {done: false, value: 'chunk 2'}
await reader.read()
// {done: false, value: 'chunk 3'}
await reader.read()
// {done: true, value: undefined}
what a reader does is lock the stream to itself so no other reader would read from the stream. I guess because it's jealous, just kidding 😄. The reason is that a stream handles one chunk at a time, and if we have two readers, those two readers might be at a different stage of reading (consuming) from the parent stream, or one of them might cancel the stream which would interfere with the other reader (consumer).
Teeing (T)
I won't go deep into this, but since we cannot have two readers from a single readable stream at the same time, we can tee that readable stream, creating two new readable streams that provide the same data. Teeing would force us to use either of those two new streams. And the original stream will be locked for them.
readable.tee()
// [ReadableStream, ReadableStream]

WritableStream
It's a stream you're supposed to write into (even if you don't have access to the controller), so it's the opposite of the ReadableStream.
But here's the catch, you can also read and track the values that are being written into this stream, but only if you are the one providing this stream. If you get to write data into this stream, you'll be called the producer.
It's usually a wrapper around the underlying sink which is a destination for the data, like the filesystem.
We have two ways of getting the data into a writable stream!
Readable Streams
When data flows into a readable stream, we can then pipe that stream into a writable stream. Like reading from the network (readable stream) and writing to a certain file on your disk (writable stream). The process that connects these two is called piping.
In a project like Waku, this approach is more common!
// readable: our readable stream from the previous example
readable.pipeTo(new WritableStream({
write(chunk) {
console.log(chunk)
}
}))
// log: chunk 1
// log: chunk 2
// log: chunk 3
Writer
For readable streams, we've been able to lock the stream and read from it directly. The same goes for a writable stream, with writers we'll be able to write into a writable stream directly!
const writable = new WritableStream({
write(chunk) {
console.log(chunk)
// imagine everytime we get a chunk, we write it directly to a file
}
})
const writer = writable.getWriter()
writer.write('chunk 1')
// log: chunk 1
writer.write('chunk 2')
// log: chunk 2
writer.write('chunk 3')
// log: chunk 3
TransformStream
It's a stream that is mainly used for transforming the chunks we receive. It gives us two streams, one readable and one writable! We write into the writable, and the chunks will be processed (transformed) by the transform function that we pass the the TransformStream, and then whatever result will be enqueued to the readable stream. Without the transform function, it will just act as a bridge between writable streams and readable streams.
// https://streams.spec.whatwg.org/#example-transform-identity
const { writable, readable } = new TransformStream();
fetch("...", { body: readable }).then(response => /* ... */);
const writer = writable.getWriter();
writer.write(new Uint8Array([0x73, 0x74, 0x72, 0x65, 0x61, 0x6D, 0x73, 0x21])); // "streams!"
writer.close();
Here's a great example, where we pass a readable as the request's body, and then we write body content using a writer from the writable stream.
const { readable, writable} = new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk.split('').reverse().join(''))
}
})
const writer = writable.getWriter()
const reader = readable.getReader()
await writer.write('olleh')
// 'olleh' -> transform() -> 'hello'
await reader.read()
// {done: false, value: 'hello'}
Here's an example of how you can reverse a string using the TransformStream!
pipeThrough
This is a method on readable streams that is useful for when we want to pipe the readable stream to the writable side of the TransformStream. And it'd return the readable side of the TransformStream.
const transformer = new TransformStream()
// instead of this
readable.pipeTo(transformer.writable)
// we can do this
readable.pipeThrough(transformer) // This would return transformer.readable
A typical example of constructing pipe chain using
pipeThrough(transform, options)would look like. whatwg
// https://streams.spec.whatwg.org/#example-pipe-chain
httpResponseBody
.pipeThrough(decompressorTransform)
.pipeThrough(ignoreNonImageFilesTransform)
.pipeTo(mediaGallery); // a pipe chain
Definitions
Internal queue
For readable streams, it's data that has been enqueued to the stream but hasn't been read by the consumer (a reader or another writable/transform stream). For writable streams, it's the data that has been written to the stream itself but still hasn't been written into the underlying sink (file system for instance).
High water mark
The boundary for the amount of data that the stream can handle in the internal queue is called high water mark. If we cross that boundary, then backpressure would be applied.
Backpressure
A signal from the consumer stream to the parent stream slows the amount of data we receive (read or write), so we first handle the current data that we have in the current internal queue.
And that's it! The concept of Streams might mean different things in different contexts, but the core idea is handling small pieces of data sequentially, no matter if it's Video Streaming or React Server Components. The concept is not that complex but generating streaming-compatible data is the challenging part, and I guess that's why it took the React team years to reach what we call today React Server components.
I'm Mohammad and this is my first essay and post on my blog, would be happy to hear your thoughts. Don't hesitate to say hello in my DM! I'm also available for hire, so let's discuss that if you have an opportunity :)
Reviewers
Thanks to all of my friends who reviewed this document.
Resources
- https://streams.spec.whatwg.org/
- https://nodesource.com/blog/understanding-streams-in-nodejs/
- https://www.pubnub.com/guides/http-streaming/
- https://cycle.js.org/streams.html